
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 자동화
- FastAPI
- 모델서빙
- datetime #zip
- 파일저장
- aiflow
- 빗썸api
- 원하는 태그 찾기
- airflow
- text.children
- requests
- 정규표현식
- Google Cloud Storage
- 가상환경 초기세팅
- requesthead
- mariadb설치 #mysql설치
- enumerate #함수 # def
- JavaScripts
- cron
- pickle #datetime
- etl
- celery
- with open
- 자연어처리 환경 컨테이너
- 리눅스 # 기초
- ssh operator
- K-ICT
- Docker
- HeidiSQL
- beautifulsoup
Archives
- Today
- Total
오음
Word2Vec모델 본문
- TF-IDF 메모리 문제 해결
- 통계 기반의 방법 단점
- 대규모 말뭉치를 다룰 때 메모리상의 문제가 발생
- 높은 차원을 가짐, 매우 sparse한 형태의 데이터임
- 한번에 학습 데이터 전체를 진행함
- 큰 작업을 처리하기 어려움
- GPU와 같은 병렬처리를 기대하기 힘듬
- 학습을 통해서 개선하기가 어려움
- 대규모 말뭉치를 다룰 때 메모리상의 문제가 발생
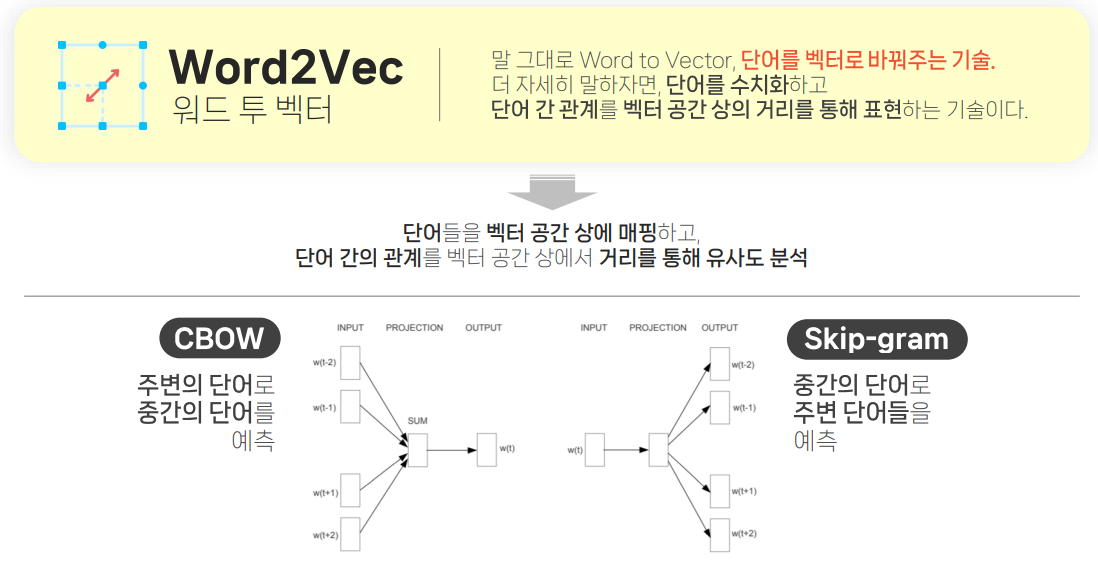
해결 방안이 Word2Vec임
- 추론 기반의 방법
- 주변 단어(맥락)이 주어졌을 때 “?”에 무슨 단어(중심 단어)가 들어가는지를 추측하는 작업
- 정의
- Word2Vec은 단어간 유사도를 반영하여 단어를 벡터로 바꿔주는 임베딩 방법론
- 원-핫 벡터 형태의 sparse matrix가 가지는 단점을 해소하고자 저차원의 공간에 벡터로 매핑하는 것이 특징
- 비슷한 위치에 등장하는 단어들은 비슷한 의미를 가진다.
- 알고리즘
- CBOW
- 주변에 있는 단어들을 가지고, 중간에 있는 단어들을 예측하는 방법
- Skip-Gram
- 반대로 중간에 있는 단어로 주변 단어들을 예측하는 방법
- CBOW
CBOW


1. 입력 값 받음
2. w_input을 initialize(형태맞게) 해서 두개를 곱해서 히든레이어 만든다.
3. w_ouput도 initialize 똑같이 작업 후에 은닉층과 곱해서 출력층의 점수로 만들고 확률로 바꾸기 위해서 softmax를 사용
4. 계산한 Loss를 가지고 Backpropagation 과정
Skip-gram


word2vec을 이용한 사용자 플레이리스트 기반 추천 모델 생성
df = pd.read_csv("/root/data/sing_list/total_final.csv")
# 실제 사용자 플레이리스트와 원래 수집한 플레이리스트를 합쳐주는 과정
df = pd.concat([df,new_playlist]).reset_index(drop=True)
df = df[~(df['master_number']=='?')]
df['master_number'] = df['master_number'].apply(lambda x : str(int(x)))
play = df.groupby('Category').agg(list).reset_index()['master_number']
# 알맞은 형태로 전처리
output_list = [lst for lst in play if len(lst) > 3]
logging.basicConfig(format="%(asctime)s : %(levelname)s : %(message)s", level=logging.INFO)
# Word2Vec 모델 학습 시 에포크마다 호출되어 학습 상황을 출력하고 기록하는 역할
class Callback(CallbackAny2Vec):
def __init__(self):
self.epoch = 1
self.training_loss = []
def on_epoch_end(self, model):
loss = model.get_latest_training_loss()
if self.epoch == 1:
current_loss = loss
else:
current_loss = loss - self.loss_previous_step
print(f"Loss after epoch {self.epoch}: {current_loss}")
self.training_loss.append(current_loss)
self.epoch += 1
self.loss_previous_step = loss
model = Word2Vec(
vector_size=256,
window = 10,
min_count = 3,
sg = 1,
negative = 20,
workers = multiprocessing.cpu_count()-1)
logging.disable(logging.NOTSET)
t = time()
model.build_vocab(output_list)
logging.disable(logging.INFO)
callback = Callback()
t = time()
model.train(output_list,
total_examples = model.corpus_count,
epochs = 100,
compute_loss = True,
callbacks = [callback])
model.save("song2vec.model")
Word2Vec 모델 인스턴스 생성
- vector_size: 임베딩 벡터의 차원
- window: 주변 단어(window) 크기
- min_count: 단어 최소 등장 횟수
- sg: Skip-gram 방식 사용 여부(0은 CBOW, 1은 Skip-gram)
- negative: 네거티브 샘플링 수
- workers: 작업에 사용할 프로세스 수
Word2Vec 모델 학습
- total_examples : 처리할 문장 개수
- epochs : 반복학습(epoch) 횟수
- compute_loss : 손실 계산 여부
- callbacks : 콜백 함수 설정
각 음악(곡 번호)에 대한 벡터 임베딩을 학습하며, 곡들 사이의 유사성을 파악
'데이터 분석' Related Articles
more
