
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- requesthead
- 가상환경 초기세팅
- FastAPI
- 빗썸api
- ssh operator
- 자연어처리 환경 컨테이너
- text.children
- mariadb설치 #mysql설치
- 파일저장
- 원하는 태그 찾기
- 정규표현식
- enumerate #함수 # def
- Docker
- aiflow
- 리눅스 # 기초
- 자동화
- HeidiSQL
- airflow
- datetime #zip
- etl
- K-ICT
- JavaScripts
- beautifulsoup
- with open
- Google Cloud Storage
- cron
- celery
- 모델서빙
- pickle #datetime
- requests
- Today
- Total
오음
Airflow) GPU서버를 이용한 모델 학습과 학습된 모델 버킷에 저장하기 본문
사용자들의 플레이리스트들을 수집해서 word2vec모델을 학습 후 새로운 사용자의 리스트를 보고 추천해주는 시스템을 만들고 싶었다. (더 공부한 후 포스팅예정!)
거의 2주간은 필요한 데이터 수집과 데이터 전처리에 많은 시간을 쏟은 것 같았다. 그럼에도 필요 데이터 수집은 계속해서 이루어져야 한다.. 왜냐? 모델 학습을 계속 진행해서 더 많은 데이터로 학습하게 만들어야 되기 때문이다. 이 과정을 airflow를 통해서 만들어진 코드들이 자동화 될 수 있게 만들어 줄 것이다.
airflow 진행순서)
멜론,바이브,지니,스포티파이등등의 user 플레이리스트 크롤링 + 배포될 경우 새로운 사용자들의 리스트
-> 모델 학습 -> 모델 저장 -> 백엔드로 모델 서빙
여기서 플레이리스트 크롤링과 배포될 경우 새로운 사용자들의 리스트들은 독립적인 dag파일을 만들어 DB,cloud storage에 저장하게 만들었고 지금 시작할 내용은 바로바로 ! 수집한 사용자의 리스트들을 가지고 모델을 학습하고 버킷으로 저장하는 dag파일을 만드는 것이다.
수집한 데이터의 양이 그렇게 많지 않아 word2vec 모델은 무겁지 않아 따로 GPU를 쓰면서까지 학습 시키지 않아도 되지만 모든 모델링 관련된 코드들은 k-ict에서 제공하는 GPU 컨테이너 안에서 진행하고 싶었다.
※ 시작하기 앞서 나는 몇가지 자동화 고민을 해보았다.
plan1) GPU 컨테이너 내부에서 airflow를 띄워서 자동화?
plan2) 맘편하게 GPU 컨테이너에서 cron을 통해 자동화 후 버킷으로 보내는 코드를 짜야하나?
plan3) 원래 만들어 놓은 airflow컨테이너(dag파일들이 모여있는) 와 GPU서버를 연결해야할까?
첫 번째와 두 번째 방법은 사실 크게 고민하지 않고 실행하면 되는 건데 컨테이너끼리 서로 통신하는 세 번째 방법으로 하고 싶었다.
방법을 알고 나니 간단했다.
1. GPU컨테이너와 airflow컨테이너 사이의 통신을 연결해 준다. (뭘로? ssh)
2. airflow dag파일에서 몇 가지 operator 중 sshoperator를 통해서 파이썬 파일을 실행할 커맨드 명령어만 추가해 준다.
3. GPU 주피터 서버에서 실행될 python코드에 플레이리스트를 불러오고 학습하고 모델을 버킷으로 저장을 시켜주는 코드를 짠다.
자 그럼 Start!
1. GPU컨테이너와 Airflow컨테이너 사이의 통신
k-ict에서 할당해 준 컨테이너는 기본적으로 ssh 통신을 할 수 있게 세팅이 되어있다. Host와 Port번호 비밀번호를 알려준다. 이걸 이용해서 Airflow와 ssh를 통해 통신할 수 있었다. Airlfow의 Admin - connection에 등록만 시켜주면 된다.
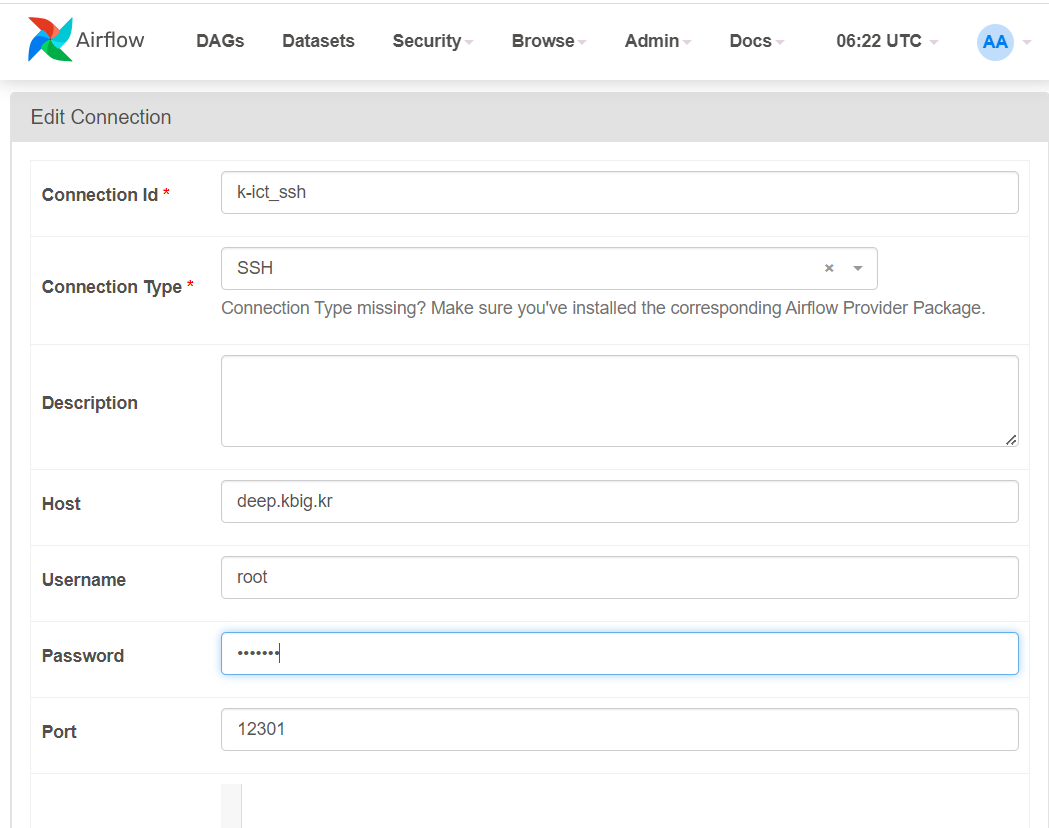
※ 비밀번호는 해당 GPU서버 컨테이너 가서 바꾸면 된다.
위에 입력한 정보가 맞는지 gpu서버 컨테이너와 ssh연결을 해본다. 연결이 잘 된 것을 확인할 수 있었다.

2. 등록을 시켜주었다면 바로 dag파일로 가보자!
from datetime import datetime, timedelta
from airflow import DAG
from airflow.providers.ssh.operators.ssh import SSHOperator
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2023, 1, 1),
'email_on_failure': False,
'email_on_retry': False,
'retries': 3,
'retry_delay': timedelta(minutes=2), # 재시도 간격
}
dag = DAG(
dag_id='run_model_on_remote_container',
default_args=default_args,
description='Run model.py on k-ict container',
schedule_interval='0 0 15 * *',
catchup=False
)
run_model_on_container = SSHOperator(
task_id='run_model_on_container',
ssh_conn_id='k-ict_ssh',
command='/opt/conda/bin/python /root/data/sing_list/song2vec.py',
cmd_timeout=30.0 * 60,
dag=dag
)
dag 파일은 별 거 없다. 우선 default_args들로 기본 인수들을 설정하고
dag 설정에서 배치 스케줄을 매월 15일 00시 00분에 실행을 하도록 시켰다.
SSHOperator는 원격 시스템에서 SSH를 통해 명령어를 실행할 수 있는 오퍼레이터이다. SSHOperator를 이용하여 run_model_on_container라는 작업을 정의하고 command를 통해서 내가 만든 파이썬 파일을 실행시켜 주면 된다.
이 파이썬 파일에는 플레이리스트들을 불러와 모델 학습을 하고 버킷에 저장하는 내용의 파이썬 파일이다.
/opt/conda/bin/python은 gpu컨테이너 내부의 파이썬 경로이다. (which python으로 경로 확인)
/root/data/sing_list_song2cec.py는 gpu컨테이너 내부의 실제 파이썬 파일이 있는 경로이다.
cmd_timeout은 명령어 실행에 대한 타임아웃이고 나는 30분으로 설정했다.
3. airflow의 command명령으로 실행될 song2vec.py 파일 만들기
GPU컨테이너 안에 있는 song2vec.py 파일이다. airflow실행 시 이 파일이 돌아갈 것이다.
먼저 해당 파일이 돌아가려면 당근이지 필요한 라이브러리를 gpu컨테이너에 다운 받아야 한다.
word2vec을 이용하기 위해 gensim 패키지를 사용하였고 , 버킷에 저장시키기 위해 google관련 라이브러리도 받아야 한다. 할 거 많네 ㅋㅋ 그래서 버킷에 올리는 코드는 아래에 있는 블로그를 참조하였다.
에어플로우(크롤링>>버킷) + .env파일 다루는 법
에어플로우, gcp, gcs, .env파일
velog.io
<song2vec.py>
import pandas as pd
import numpy as np
from gensim.models import Word2Vec
from gensim.models.callbacks import CallbackAny2Vec
from sklearn.model_selection import train_test_split
from sklearn.manifold import TSNE
from scipy import stats
# Additional
import math
import random
import itertools
import multiprocessing
from tqdm import tqdm
from time import time
import logging
import pickle
from google.cloud import storage
# 플레이리스트 불러오기
df = pd.read_csv("/root/data/sing_list/total_mapping_playlist/total_playlist2.csv")
df['master_number'] = df['master_number'].apply(lambda x : str(int(x)))
play = df.groupby('Category').agg(list).reset_index()['master_number']
output_list = [lst for lst in play if len(lst) > 3]
logging.basicConfig(format="%(asctime)s : %(levelname)s : %(message)s", level=logging.INFO)
class Callback(CallbackAny2Vec):
def __init__(self):
self.epoch = 1
self.training_loss = []
def on_epoch_end(self, model):
loss = model.get_latest_training_loss()
if self.epoch == 1:
current_loss = loss
else:
current_loss = loss - self.loss_previous_step
print(f"Loss after epoch {self.epoch}: {current_loss}")
self.training_loss.append(current_loss)
self.epoch += 1
self.loss_previous_step = loss
# 모델 정의
model = Word2Vec(
vector_size=256,
window = 10,
min_count = 1,
sg = 0,
negative = 20,
workers = multiprocessing.cpu_count()-1)
logging.disable(logging.NOTSET) # enable logging
t = time()
model.build_vocab(output_list)
logging.disable(logging.INFO) # disable logging
callback = Callback() # instead, print out loss for each epoch
t = time()
# 모델 학습
model.train(output_list,
total_examples = model.corpus_count,
epochs = 100,
compute_loss = True,
callbacks = [callback])
model.save("song2vec.model")
key_path = "/root/env/key.json"
# 저장한 모델 구글 클라우드 스토리지 보내기
def upload_to_gcp(file_path, bucket_name, destination_blob_name):
"""Uploads a file to Google Cloud Storage."""
storage_client = storage.Client.from_service_account_json(key_path)
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(destination_blob_name)
blob.upload_from_filename(file_path)
upload_to_gcp("/root/song2vec.model", "song2vec", "song2vec.model")
4. 자 이제 위에서 한 모든 것들을 airflow로 돌려보겠다. 고 슈~웃!
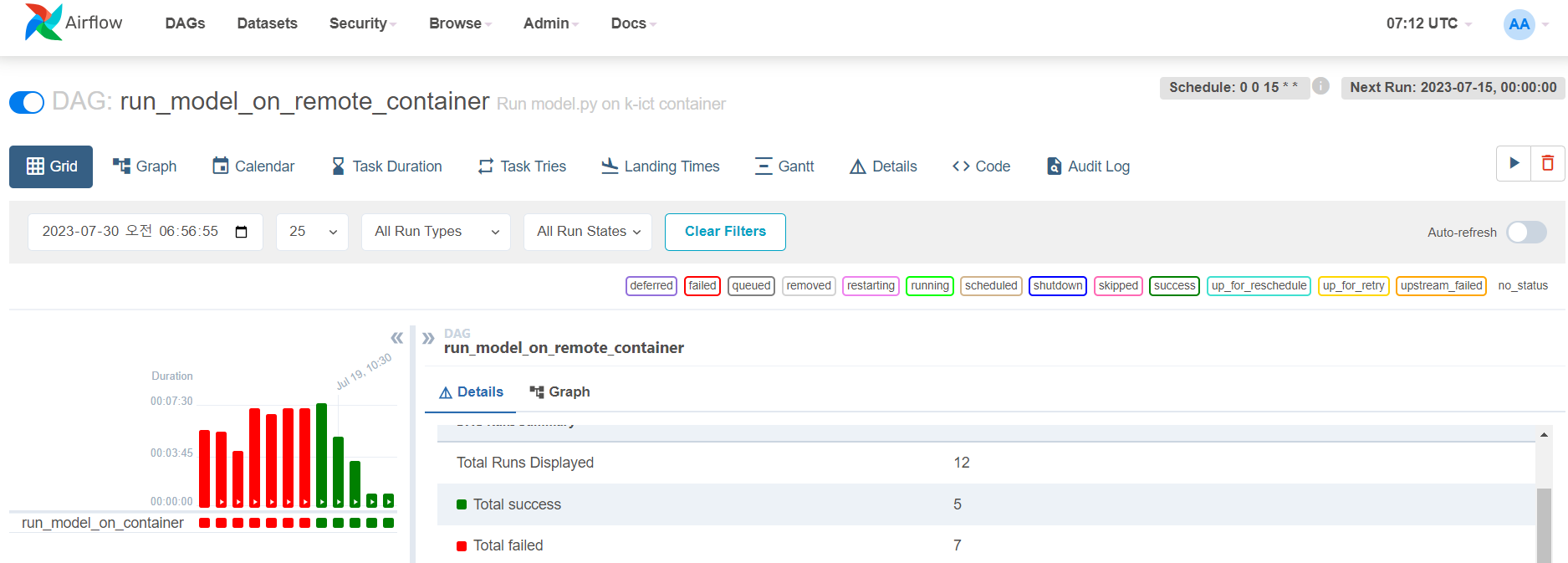
실패 7번 정도면 양호하다 ㅋㅋㅋ
자 이제 결과를 확인해볼까
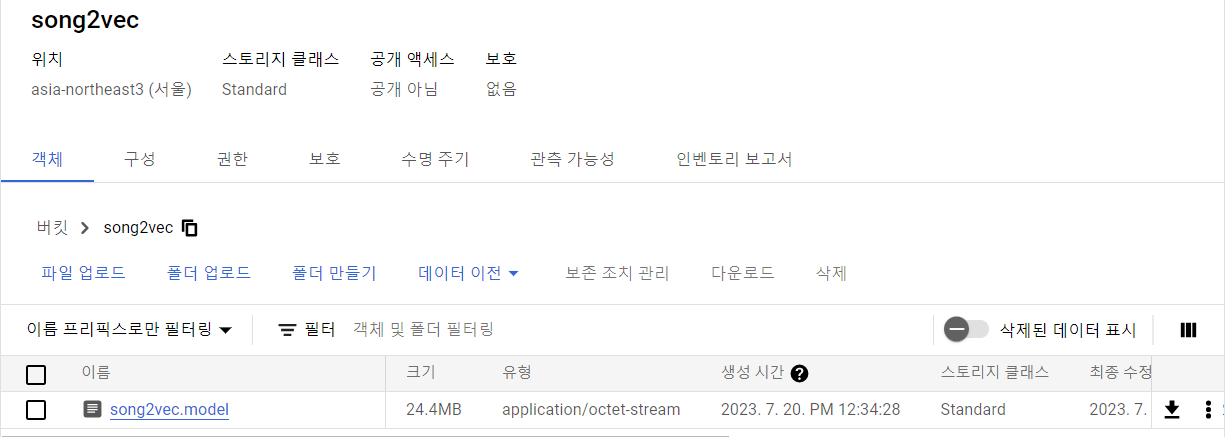
휴~ 다행 .. model 파일이 저장된 걸 볼 수 있었다.
다음 단계) 자 이제 다음 step은 이 모델을 fastapi에 보내주는 dag을 짜고 dag끼리의 dependency를 사용해 순차적으로 처리할 airflow를 구성해 보겠다.
dag1 : 플레이리스트 크롤링 후 적재
dag2 : 모델 학습 모델 저장
dag3 : fastapi에 모델 가져다주기
이 세 개의 dag이 순서대로 행해져야 함! 처음엔 각각의 dag 파일에서 시간을 조금 다르게 설정할까 싶었지만 Airflow에서는 2.1 버전부터 DAG 내 task들 뿐만 아니라 DAG 간의 dependency를 설정할 수 있는 기능도 제공한다고 한다.

'데이터 엔지니어링 > Airflow' 카테고리의 다른 글
| Airflow와 몽고DB (0) | 2023.06.02 |
|---|---|
| Airflow 컨테이너 띄우기 (0) | 2023.05.31 |

